Introduction
With the phenomenal increase of data collection from genome sequencing projects and new experimental methods, is it fundamental to triage and contextualize this biological input. A pathway database is an effort to handle the current knowledge of biochemical pathways and in addition can be used for interpretation of sequence data.
Some existing pathway databases are considered as detailed functional genomic annotations, but mostly experimental data are lacking in these databases.
This resource will focus primarily on 2 databases dedicated to biological pathways: KEGG and Reactome, 2 of the most used and critical databases in biology.
History & Description
KEGG
The KEGG database project (KEGG stands for Kyoto Encyclopedia of Genes and Genomes) was initiated in 1995 by Minoru Kanehisa from Kyoto University (1). With the ‘Cyc’ databases (2), it is one the oldest biological database in the world.
KEGG is composed of multiple databases from genomes, biological pathways, diseases, drugs and chemical substances. It is mainly used in research from genomics, metagenomics to metabolomics and others.
KEGG PATHWAYS database (3) is a collection a manually drawn maps that represents experimental knowledge on metabolism of cells and organisms. Each pathway contains molecular interactions and reactions. It links genes (from the genome) to the proteins in the pathway.
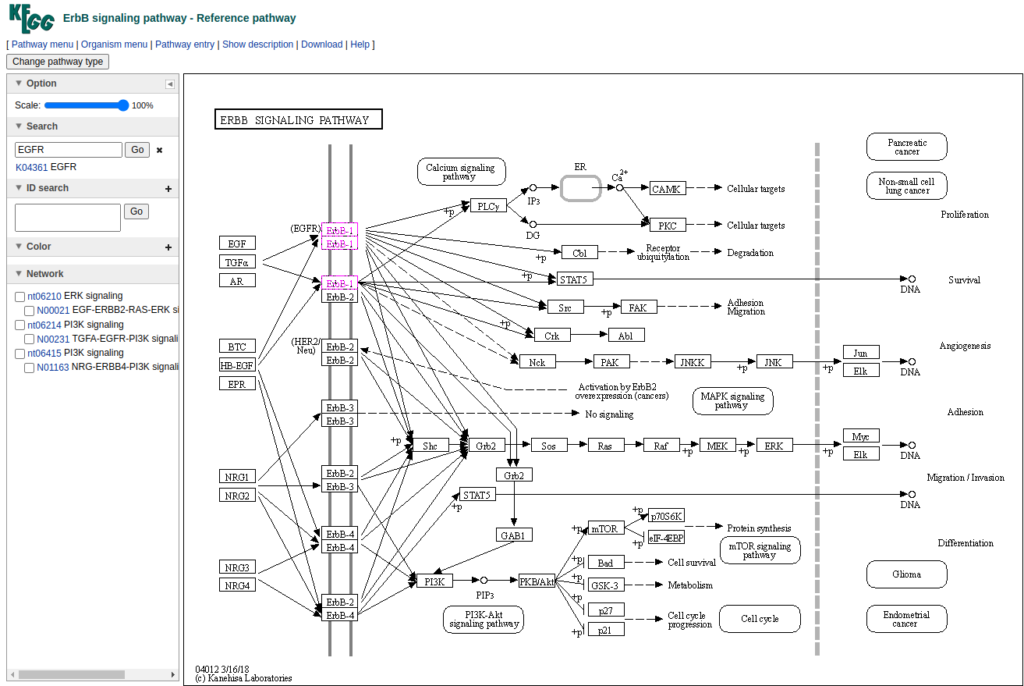
The KEGG PATHWAY database is the core component of the KEGG sphere. It can connect many entities including genes, RNAs, proteins, glycans, chemical reactions, and more. On top of these, another ontology database, called KEGG BRITE, contains hierarchical classifications of the various entities and supplements KEGG PATHWAY.
Reactome
Another critical pathway database in biology is Reactome (4), created in 2003 by a collective of scientists from OICR, NYU Langone Health, EMBL-EBI and OHSU.
Reactome is open-source, open-access, manually curated and peer-reviewed. Its main goal is to support basic and clinical research, genome analysis, modeling and system biology by providing a collection of tools for the visualization, interpretation and analysis of pathway knowledge. Reactome is a relational database of signaling and metabolic molecules and contains their relations organized into biological pathways and processes.
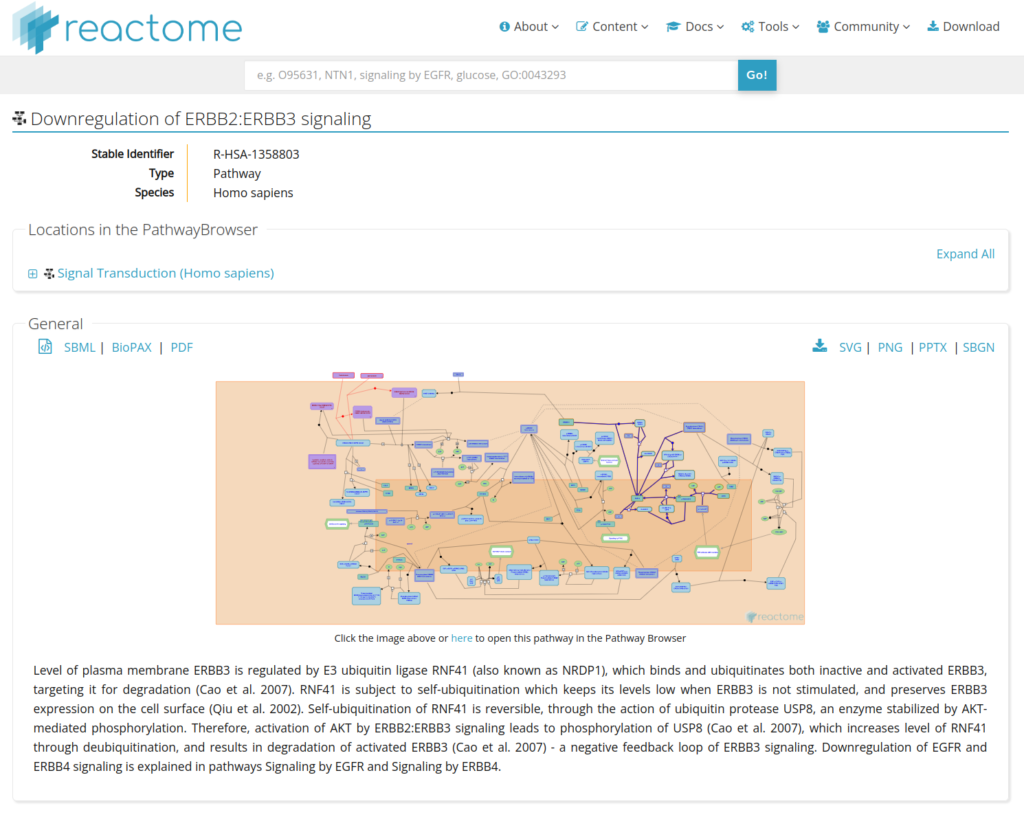
The core unit of Reactome data model is the reaction. Therefore, entities participating in reactions form a network of biological interactions and are assembled into pathways.
The curation process that goes into Reactome pathway is of the same order than edition of a scientific review: First expert from an external domain provides an expertise on the pathway. Second, a curator from Reactome formalizes the pathway into the database structure. Third, another external expert reviews the final representation. The pathway’s modifications and evidence are tracked throughout the entire process and backed up with scientific literature.
Finally, Reactome cross-references with more than 100 different resources, including NCBI Gene, Ensembl, UniProt, UCSC Genome Browser, ChEBI or PubMed.



